
0. 개요
현재 특정 대역의 서버들은 윈도우로 구성된 NTP 서버의 시간을 동기화하여 사용한다고 가정한다.
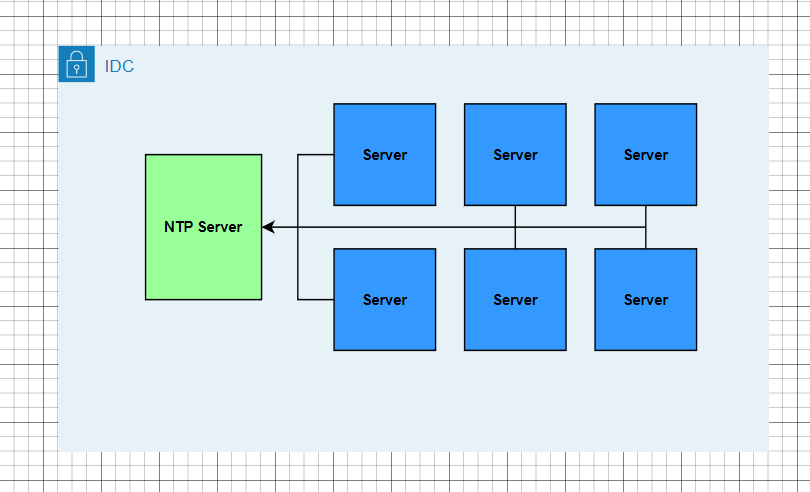
그런데 이 NTP 서버 시간대가 실제 시간대와 점차 차이가 벌어진다.
- 원인은 네트워크 지연, ntp 설정 문제, 시스템 리소스(CMOS 배터리 등 물리적 부품의 문제) 등 여러 경우가 있어 보임
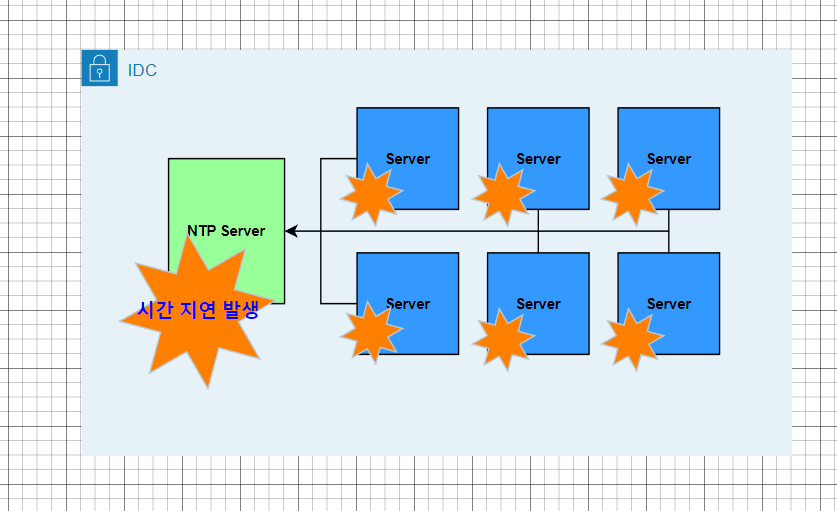
이에 윈도우 서버의 시간을 모니터링하여 실제 시간과 차이가 30초 이상 발생하면 Slack 알람이 발송되도록 모니터링하는 방법을 알아보겠다.
1. win_exporter 구성
NTP 서버에 win_exporter 설치를 진행한다.
Win_exporter 이름으로 윈도우 서비스를 등록했으며, 이를 실행 및 자동 실행 설정을 진행한다.
sc create "Win_exporter" binPath= "C:\infra_mon\windows_exporter.exe
--collectors.enabled \"[defaults],process,container,time\""
- collectors로 flag를 추가할 수 있다.(자세한 flag 정보는 win_exporter Github 참조)
- 기본 항목인 defaults 외 동작하는 프로세스(process), 컨테이너(container) 시간 항목(time) 을 가져오도록 구성하였다.
exporter 구성 중 문제발생 (windows version 이슈)
해당 sc create 명령으로 다른 윈도우 서버들은 모두 구성이 완료되었으나, 본인이 구성한 NTP 서버의 경우 win_2008 버전으로 버전 호환이 안되어 실행이 불가하다. (default만 가능하다..)
이 경우 기본적인 os, cpu, mem 모니터링만 가능하고 시간 등의 정보를 가져올 수 없다.
생각할 수 있는 방법은 다음과 같다.
- 방법 1. win_exporter 다른 버전으로 재 구성
- 방법 2. 스크립트로 시간대를 직접 파일로 저장하여 이를 exporter에 싣기
+ 추가 확인된 내용
1. 현재 윈도우 2008은 win_exporter 최신버전이 실행되지 않는다. (241028 기준 v0.28.2)
그래서 2019 생성된 v0.8.0 버전으로 실행중이며 해당 버전에서 time 옵션이 가능한 지 확인이 필요하다.
2. v0.8.0은 win_exporter가 아닌 wmi_exporter로 쿼리문에 차이가 있다.
즉 기존 win_exporter 쿼리가 아닌 wmi_exporter 쿼리로 수정하여 기존 대시보드와 통합해야 할 것 같다.
(쿼리문이 살짝 다르다.)
2. promql 구성
윈도우 서버의 os 시간대를 가져오는 쿼리를 구성한다.
win_exporter
windows_os_time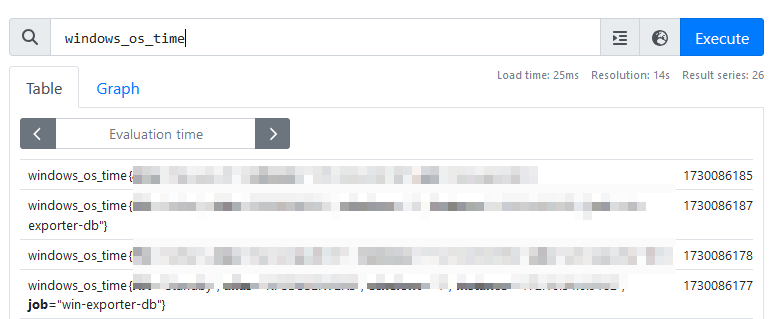
wmi_exporter
wmi_os_time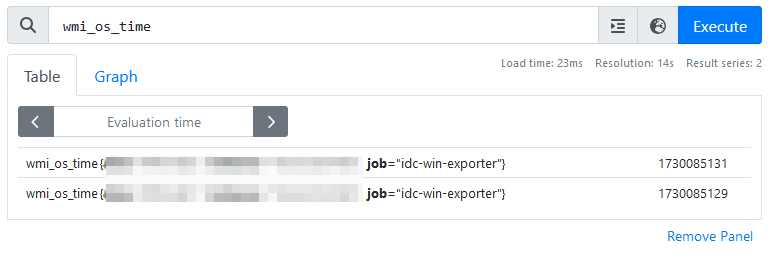
두 쿼리 모두 밀리초로 데이터가 동일하게 나타난다.
3. Grafana 구성
우선 결과부터 보자면 다음과 같다.
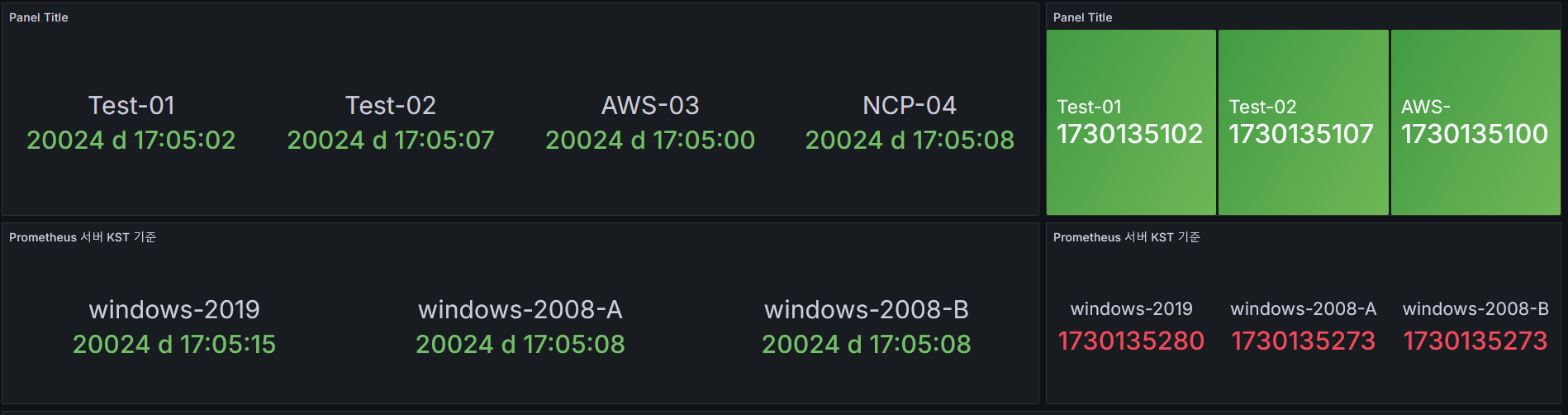
테스트로 온프레미스 서버 5대, AWS EC2 1대, NCP server 1대로 진행했으며,
NCP와 AWS는 각자 플랫폼에서 지원하는 기본 NTP 서버로 연결되어있고, 온프레미스 5대는 windows 2008 -A (NTP) 서버에 NTP 설정이 되어있다.
일단 한 줄에 좌측과 우측은 모두 같은 데이터이며, 좌측은 시간 형식에 맞춰서 구성하였고 우측은 promql 결과값인 밀리초 그대로 나타내었다.
- 위 promql 결과값(밀리초)에서 32400(9시간)을 더해 KST 시간을 맞추었다.
이렇게 만들고 보니 문제가 있는데, 일단 해당 결과가 완전히 정확하지 않다.
prometheus 서버에서 각 exporter 메트릭을 확인하는 형식인데 이미 여기서부터 실제 정확한 시간과는 차이가 발생한다.
현재 30초에 한 번씩 메트릭을 수집하도록 설정하였기 때문이다.
- 해결방법 : time 결과값만 발송하는 메트틱 exporter를 따로 구성해서 해당 exporter만 매 초, 혹은 짧은 시간동안 지속적으로 보내는 방법
또한 prometheus 서버는 NCP에 구성했고, 모니터링 대상 서버들은 AWS, NCP 등 여러 리전에 존재한다.
즉, 온프레미스 서버나 AWS 서버에서는 당연히 네트워크 속도의 차이가 발생할 수 밖에 없다.
- 계속 새로고침해서 확인해보면, NCP 서버들과 다른 플랫폼 서버들의 차이가 확연하다.
- 짧은 시간의 차이가 발생하는 것이 문제가 없다면 괜찮겠지만, 정확한 모니터링 방안이 될 수는 없을 것 같다.
그래도 현재 요청사항은 30초, 1분 이상 차이가 발생하면 인지할 수 있는 정도라 어느정도 차이가 발생하더라도 모니터링은 진행할 수 있을 것 같다.
일단 알람 설정을 구성하고 추후 개선하도록 해보겠다.
4. 알람 구성
일단 위 promql 결과값은 밀리초는 (ex. 1730136017) *세계 협정 시간을 기준으로 얼마나 흘렀는지를 기준으로 나타난다.
즉, *1970년 1월 1일 00:00:00 (UTP) 이후 얼마나 지났는지를 초 단위로 나타내어 확인하는 것으로, 1730136017라는 값을 해석하면 2024년 10월 28일로 나타난다.
우리는 해당 promql 결과값은 밀리초를 기준으로 30초 이상 차이가 발생하면 slack 알람이 오도록 구성해보겠다.
기준점을 NCP 서버로 잡고, 사내 개발서버 2대를 NCP 서버와 비교해보겠다. 쿼리문은 다음과 같다.
A 쿼리 : sum by (alias) (windows_os_time{alias="Test-01"} + 32400)
A 쿼리 결과 : {alias="Test-01"} 1730147790
B 쿼리 : sum by (alias) (windows_os_time{alias="Test-02"} + 32400)
B 쿼리 결과 : {alias="Test-02"} 1730147776
C 쿼리 : ($A - $B) > 30
C 쿼리 결과 : Expression warning
2 items dropped from union(s):
["$A - $B": ($A: {alias=Test-01}) ($B: {alias=Test-02})]
그러나 위 쿼리는 동작하지 않는다. 이유는 다음과 같다.
grafana math 사용 중 문제 발생(동일한 결과/라벨에서만 비교 가능)
math에서는 동일한 결과(라벨) 값만 비교가 가능하다.
즉, 대상이 다른 결과에 대해서는 사용할 수 없다.
보통 동일 대상의 시간대 별 비교나 일치하는지 확인하는데 사용하는 듯 하다.
(전날, 현재 비교 등...)
해결. math 중복 처리 방법
https://grafana.com/docs/grafana/latest/panels-visualizations/query-transform-data/expression-queries/
Write expression queries | Grafana documentation
Getting started with managing your metrics, logs, and traces using Grafana In this webinar, we’ll demo how to get started using the LGTM Stack: Loki for logs, Grafana for visualization, Tempo for traces, and Mimir for metrics.
grafana.com
Grafana의 Alerting Expression에서 Math나 Reduce를 사용하는 경우, 두 쿼리의 비교는 동일한 라벨 집합을 가져야한다.
Prometheus 데이터의 특성상, 라벨이 다르면 서로 다른 시계열로 간주되므로, 각기 다른 라벨을 가진 쿼리 결과는 기본적으로 직접 비교가 불가능하며 Grafana에서도 마찬가지로 Math, Reduce, 임계값 비교 등에서도 동일한 원리로 작동한다고한다.
math는 동일한 라벨에서만 비교가 가능하고,
본인은 label_replace 함수를 이용하여 prometheus 시계열 메트릭의 라벨을 수정한 것이다.
label_replace
Prometheus 쿼리 언어(PromQL)*에서 제공하는 함수로, 시계열 메트릭의 라벨을 추가, 수정, 또는 변경하는 데 사용
결국 전혀 다른 두 개의 쿼리 결과값을 grafana meth에서 사용할 수 있도록, 동일하게 보이도록 수정한 것이라고 볼 수 있다.
수정본
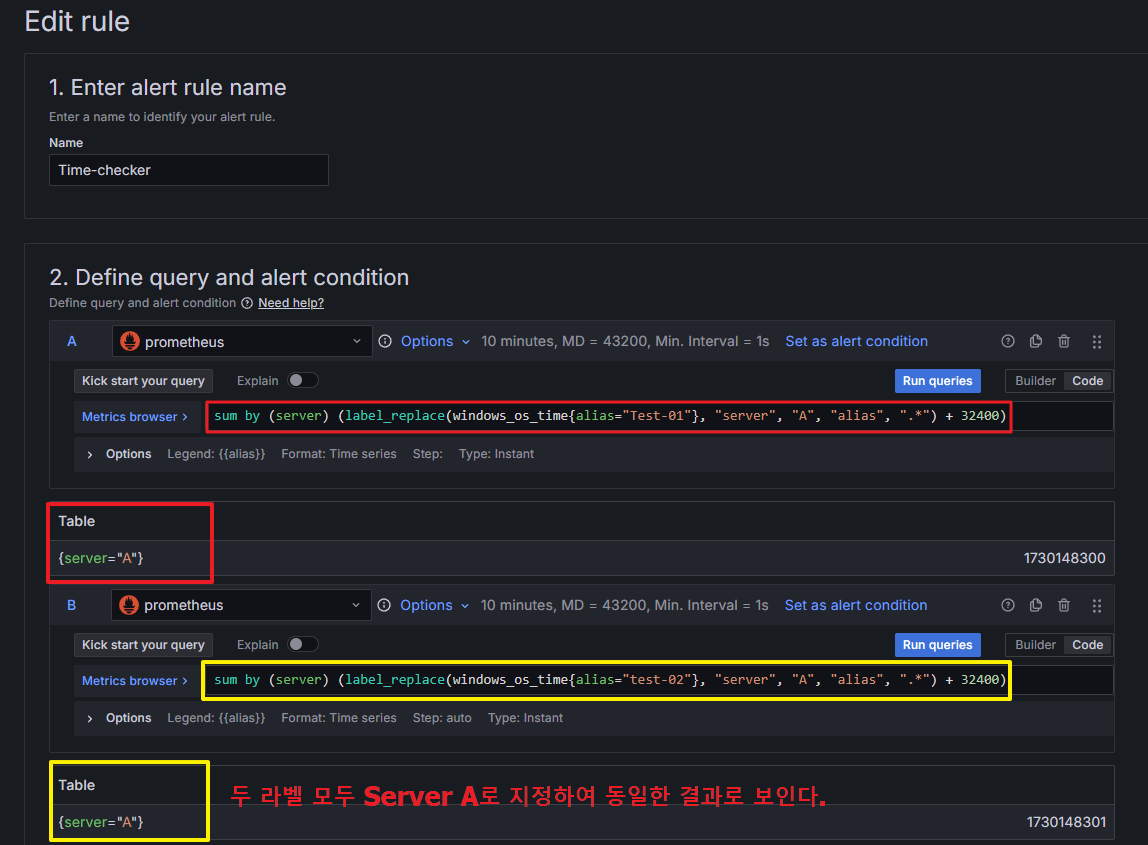
sum by (server) (label_replace(windows_os_time{alias="Test-01"}, "server", "A", "alias", ".*") + 32400)
sum by (server) (label_replace(windows_os_time{alias="Test-02"}, "server", "A", "alias", ".*") + 32400)
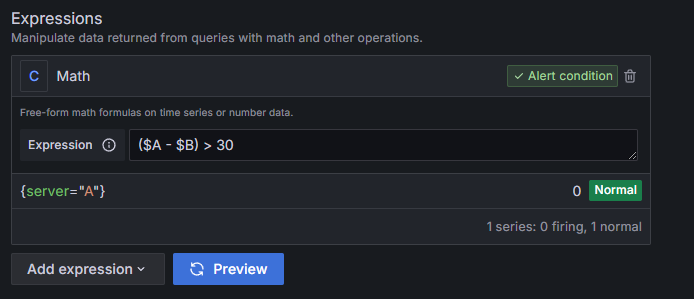
($A - $B) > 30
label_replace 함수로 두 쿼리의 결과값이 Server A로 동일하게 나타난다.
math로 두 쿼리 결과의 차이가 30보다 크면 alert이 발생하도록 구성하였다.
5. 마무리
이렇게 두 서버의 시간대를 비교하여 30초의 차이가 발생할 시 메신저 알람이 발송되도록 구성을 해보았다.
물론 아직 각 서버 시간 정보를 가져오는 시간(속도)나, 네트워크 지연으로 오차 가능성도 염두해 두어야 하여 아직 개선사항이 많아 보인다.
그래도 일단 시간 차이가 크게 발생하여 발생할 문제는 어느정도 방지할 수 있고, 추후에는 NTP 연결 정보를 모니터링하는 형식으로 상세화 해 보려 한다.
읽어주셔서 감사합니다 ~ !
'DevOps > Monitoring_모니터링' 카테고리의 다른 글
| [Prometheus] 프로메테우스 config reload (0) | 2024.08.05 |
|---|---|
| [Prometheus] 프로메테우스 데이터 기본 저장경로 (+docker compose) (0) | 2024.07.09 |
| [Prometheus] 프로메테우스 데이터 마이그레이션 (docker volume 옵션) (0) | 2024.07.08 |
| [Prometheus] 프로메테우스 기본 구성 (docker compose 생성) (0) | 2024.06.17 |
| [Grafana] Grafana Image Renderer (1) | 2023.11.20 |
0. 개요
현재 특정 대역의 서버들은 윈도우로 구성된 NTP 서버의 시간을 동기화하여 사용한다고 가정한다.
그런데 이 NTP 서버 시간대가 실제 시간대와 점차 차이가 벌어진다.
- 원인은 네트워크 지연, ntp 설정 문제, 시스템 리소스(CMOS 배터리 등 물리적 부품의 문제) 등 여러 경우가 있어 보임
이에 윈도우 서버의 시간을 모니터링하여 실제 시간과 차이가 30초 이상 발생하면 Slack 알람이 발송되도록 모니터링하는 방법을 알아보겠다.
1. win_exporter 구성
NTP 서버에 win_exporter 설치를 진행한다.
Win_exporter 이름으로 윈도우 서비스를 등록했으며, 이를 실행 및 자동 실행 설정을 진행한다.
sc create "Win_exporter" binPath= "C:\infra_mon\windows_exporter.exe
--collectors.enabled \"[defaults],process,container,time\""
- collectors로 flag를 추가할 수 있다.(자세한 flag 정보는 win_exporter Github 참조)
- 기본 항목인 defaults 외 동작하는 프로세스(process), 컨테이너(container) 시간 항목(time) 을 가져오도록 구성하였다.
exporter 구성 중 문제발생 (windows version 이슈)
해당 sc create 명령으로 다른 윈도우 서버들은 모두 구성이 완료되었으나, 본인이 구성한 NTP 서버의 경우 win_2008 버전으로 버전 호환이 안되어 실행이 불가하다. (default만 가능하다..)
이 경우 기본적인 os, cpu, mem 모니터링만 가능하고 시간 등의 정보를 가져올 수 없다.
생각할 수 있는 방법은 다음과 같다.
- 방법 1. win_exporter 다른 버전으로 재 구성
- 방법 2. 스크립트로 시간대를 직접 파일로 저장하여 이를 exporter에 싣기
+ 추가 확인된 내용
1. 현재 윈도우 2008은 win_exporter 최신버전이 실행되지 않는다. (241028 기준 v0.28.2)
그래서 2019 생성된 v0.8.0 버전으로 실행중이며 해당 버전에서 time 옵션이 가능한 지 확인이 필요하다.
2. v0.8.0은 win_exporter가 아닌 wmi_exporter로 쿼리문에 차이가 있다.
즉 기존 win_exporter 쿼리가 아닌 wmi_exporter 쿼리로 수정하여 기존 대시보드와 통합해야 할 것 같다.
(쿼리문이 살짝 다르다.)
2. promql 구성
윈도우 서버의 os 시간대를 가져오는 쿼리를 구성한다.
win_exporter
windows_os_time
wmi_exporter
wmi_os_time
두 쿼리 모두 밀리초로 데이터가 동일하게 나타난다.
3. Grafana 구성
우선 결과부터 보자면 다음과 같다.
테스트로 온프레미스 서버 5대, AWS EC2 1대, NCP server 1대로 진행했으며,
NCP와 AWS는 각자 플랫폼에서 지원하는 기본 NTP 서버로 연결되어있고, 온프레미스 5대는 windows 2008 -A (NTP) 서버에 NTP 설정이 되어있다.
일단 한 줄에 좌측과 우측은 모두 같은 데이터이며, 좌측은 시간 형식에 맞춰서 구성하였고 우측은 promql 결과값인 밀리초 그대로 나타내었다.
- 위 promql 결과값(밀리초)에서 32400(9시간)을 더해 KST 시간을 맞추었다.
이렇게 만들고 보니 문제가 있는데, 일단 해당 결과가 완전히 정확하지 않다.
prometheus 서버에서 각 exporter 메트릭을 확인하는 형식인데 이미 여기서부터 실제 정확한 시간과는 차이가 발생한다.
현재 30초에 한 번씩 메트릭을 수집하도록 설정하였기 때문이다.
- 해결방법 : time 결과값만 발송하는 메트틱 exporter를 따로 구성해서 해당 exporter만 매 초, 혹은 짧은 시간동안 지속적으로 보내는 방법
또한 prometheus 서버는 NCP에 구성했고, 모니터링 대상 서버들은 AWS, NCP 등 여러 리전에 존재한다.
즉, 온프레미스 서버나 AWS 서버에서는 당연히 네트워크 속도의 차이가 발생할 수 밖에 없다.
- 계속 새로고침해서 확인해보면, NCP 서버들과 다른 플랫폼 서버들의 차이가 확연하다.
- 짧은 시간의 차이가 발생하는 것이 문제가 없다면 괜찮겠지만, 정확한 모니터링 방안이 될 수는 없을 것 같다.
그래도 현재 요청사항은 30초, 1분 이상 차이가 발생하면 인지할 수 있는 정도라 어느정도 차이가 발생하더라도 모니터링은 진행할 수 있을 것 같다.
일단 알람 설정을 구성하고 추후 개선하도록 해보겠다.
4. 알람 구성
일단 위 promql 결과값은 밀리초는 (ex. 1730136017) *세계 협정 시간을 기준으로 얼마나 흘렀는지를 기준으로 나타난다.
즉, *1970년 1월 1일 00:00:00 (UTP) 이후 얼마나 지났는지를 초 단위로 나타내어 확인하는 것으로, 1730136017라는 값을 해석하면 2024년 10월 28일로 나타난다.
우리는 해당 promql 결과값은 밀리초를 기준으로 30초 이상 차이가 발생하면 slack 알람이 오도록 구성해보겠다.
기준점을 NCP 서버로 잡고, 사내 개발서버 2대를 NCP 서버와 비교해보겠다. 쿼리문은 다음과 같다.
A 쿼리 : sum by (alias) (windows_os_time{alias="Test-01"} + 32400)
A 쿼리 결과 : {alias="Test-01"} 1730147790
B 쿼리 : sum by (alias) (windows_os_time{alias="Test-02"} + 32400)
B 쿼리 결과 : {alias="Test-02"} 1730147776
C 쿼리 : ($A - $B) > 30
C 쿼리 결과 : Expression warning
2 items dropped from union(s):
["$A - $B": ($A: {alias=Test-01}) ($B: {alias=Test-02})]
그러나 위 쿼리는 동작하지 않는다. 이유는 다음과 같다.
grafana math 사용 중 문제 발생(동일한 결과/라벨에서만 비교 가능)
math에서는 동일한 결과(라벨) 값만 비교가 가능하다.
즉, 대상이 다른 결과에 대해서는 사용할 수 없다.
보통 동일 대상의 시간대 별 비교나 일치하는지 확인하는데 사용하는 듯 하다.
(전날, 현재 비교 등...)
해결. math 중복 처리 방법
https://grafana.com/docs/grafana/latest/panels-visualizations/query-transform-data/expression-queries/
Write expression queries | Grafana documentation
Getting started with managing your metrics, logs, and traces using Grafana In this webinar, we’ll demo how to get started using the LGTM Stack: Loki for logs, Grafana for visualization, Tempo for traces, and Mimir for metrics.
grafana.com
Grafana의 Alerting Expression에서 Math나 Reduce를 사용하는 경우, 두 쿼리의 비교는 동일한 라벨 집합을 가져야한다.
Prometheus 데이터의 특성상, 라벨이 다르면 서로 다른 시계열로 간주되므로, 각기 다른 라벨을 가진 쿼리 결과는 기본적으로 직접 비교가 불가능하며 Grafana에서도 마찬가지로 Math, Reduce, 임계값 비교 등에서도 동일한 원리로 작동한다고한다.
math는 동일한 라벨에서만 비교가 가능하고,
본인은 label_replace 함수를 이용하여 prometheus 시계열 메트릭의 라벨을 수정한 것이다.
label_replace
Prometheus 쿼리 언어(PromQL)*에서 제공하는 함수로, 시계열 메트릭의 라벨을 추가, 수정, 또는 변경하는 데 사용
결국 전혀 다른 두 개의 쿼리 결과값을 grafana meth에서 사용할 수 있도록, 동일하게 보이도록 수정한 것이라고 볼 수 있다.
수정본
sum by (server) (label_replace(windows_os_time{alias="Test-01"}, "server", "A", "alias", ".*") + 32400)
sum by (server) (label_replace(windows_os_time{alias="Test-02"}, "server", "A", "alias", ".*") + 32400)
($A - $B) > 30
label_replace 함수로 두 쿼리의 결과값이 Server A로 동일하게 나타난다.
math로 두 쿼리 결과의 차이가 30보다 크면 alert이 발생하도록 구성하였다.
5. 마무리
이렇게 두 서버의 시간대를 비교하여 30초의 차이가 발생할 시 메신저 알람이 발송되도록 구성을 해보았다.
물론 아직 각 서버 시간 정보를 가져오는 시간(속도)나, 네트워크 지연으로 오차 가능성도 염두해 두어야 하여 아직 개선사항이 많아 보인다.
그래도 일단 시간 차이가 크게 발생하여 발생할 문제는 어느정도 방지할 수 있고, 추후에는 NTP 연결 정보를 모니터링하는 형식으로 상세화 해 보려 한다.
읽어주셔서 감사합니다 ~ !
'DevOps > Monitoring_모니터링' 카테고리의 다른 글
| [Prometheus] 프로메테우스 config reload (0) | 2024.08.05 |
|---|---|
| [Prometheus] 프로메테우스 데이터 기본 저장경로 (+docker compose) (0) | 2024.07.09 |
| [Prometheus] 프로메테우스 데이터 마이그레이션 (docker volume 옵션) (0) | 2024.07.08 |
| [Prometheus] 프로메테우스 기본 구성 (docker compose 생성) (0) | 2024.06.17 |
| [Grafana] Grafana Image Renderer (1) | 2023.11.20 |